CCR + LiteLLM:讓 Claude Code 換腦不換介面
Claude Code 20x 配額大概四天左右就見底。試了一輪 CLI agent 後還是覺得 Claude Code 介面最順,所以用 claude-code-router 把 Anthropic 協議轉成 OpenAI 協議丟給 LiteLLM、把規劃留給 Claude Code、把簡單任務交給配次等模型的 subagent、把批次小任務丟給 LiteLLM 上五家官網模型、最後用 Claude Code 加 Codex 雙重驗收——這套近期慢慢試出來的工作流。
觸發點:今早那條 Codex 命令#
今天早上跑 Codex 驗收任務,命令卡在連線階段。第一反應是網路抖了,重試幾次都不行;接上 log 才看到 Codex CLI 自己被鎖住。問了一下同事才知道,公司 OpenAI workspace 的負責人帳號被停權,整個 workspace 跟著停掉——包括我們團隊在用的 Codex。
申訴信已經寄出去,OpenAI 那邊說至少三個工作天才會回覆,還不保證能救回來。所以現在驗收這層暫時只剩 Claude Code 自己跑——LiteLLM 上的小模型雖然在,但我沒打算讓它們接這層,後面講「三層分工」那節會說為什麼。Codex 那條什麼時候回得來不確定,但這個小插曲是我今天動筆寫這篇的觸發點。
真正想分享的,是過去這陣子怎麼從「Claude Code 20x 配額用著用著還是覺得不夠」,一路試到「LiteLLM 接五家官網、Claude Code 規劃、小模型跑 worker、雙 model 驗收」這套工作流。順便回頭看當初的好奇心:DeepSeek、Kimi、GLM、Grok、Qwen 這些模型真正拿來幹活,是什麼水準。
20x 為什麼還是不夠用#
Claude Code 是我的主力,訂的是 20x 級的方案。一開始用,規劃、寫、debug、驗收全部丟給它跑,配額大概四天左右就見底。直覺反應是「應該再升一階」,但 20x 已經是訂閱方案的上限,再上去只能改打 API。
回頭翻 ccusage 紀錄,發現問題不只是「用得多」這麼簡單——而是「不該用 Opus 跑的任務也在用 Opus 跑」。改 N 個檔案的同一個 import path、把 N 段 markdown 翻英文、跑 N 個 grep 整理結果,這類批次 + 機械活,用 DeepSeek V3 或 Qwen Flash 跑能省九成成本,效果差距可以忽略。
順著這條線想下去,自然就分成三層:
- 規劃這層 leverage 最高,留給最聰明的 model。任務拆分、跨檔案 reasoning、決定要不要做某個 refactor——這層用便宜的,下游全部歪掉。
- worker 這層 是體力活,越便宜越好。批次跑、可平行、機械式重複的工作丟這層。
- 驗收這層 需要「換一個視角」的價值,所以兩個 model 各看一遍比同 model 跑兩次有用。
LiteLLM 就是這時候開始研究的。一方面想找便宜的 worker model 把第二層接起來,另一方面也好奇 DeepSeek / Kimi / GLM / Grok / Qwen 這些常被討論的模型,拿來實際跑會是什麼感覺。
三層分工:規劃 / Worker / 雙重驗收#
慢慢試出來的分工長這樣:
[Claude Code] ─→ 規劃 / 制定計畫 / 拆任務 / dispatch
│
▼
[LiteLLM 上的小模型] ─→ worker:批次跑拆分後的小任務
│
▼
[Claude Code + Codex] ─→ 雙重驗收
├─ Claude Code:對照我自己訂的 coding rules 逐條檢查
└─ Codex:針對 worktree 的 git diff 跑程式碼本身的審查
規劃這層 Claude Code 本來就跑得順,繼續留著它。整套架構決策、任務拆分、跨檔案 reasoning 都在這層完成。
worker 這層 是後來補的。任務一旦被拆成「改 N 個檔案的同一個 import path」「把 N 段 markdown 翻成英文」「跑 N 個 grep 整理結果」,用 DeepSeek V3 / Qwen Flash / GLM 4.5-air 這類 $0.2/$0.5 等級的 model 跑 batch,速度跟配額壓力都好處理太多。
驗收這層用兩個 model 交叉——
- Claude Code 跑一遍,要求按「測試六鐵律」逐條打分,挑出違規處(下一節展開規則本身與來源)。
- Codex 跑另一遍,直接餵 worktree 的 git diff,要它從程式碼本身的角度找 bug、找命名不一致、找邊界條件漏處理。
兩個 model 各有盲區。Claude Code 對「我家規矩」熟,但對純語法 / 邊界錯誤的敏感度沒有 Codex 高;Codex 看 diff 仔細,但不知道我的 rules。兩者疊起來,盲區互補。
驗收這層之所以不丟給 LiteLLM 上的小模型,是因為實際試過——小模型對「找出 worker 自己沒看到的問題」這種需要審慎 reasoning 的工作,命中率明顯不夠,常常給出看起來像在審查、實際上漏掉關鍵 bug 的 review。worker 可以放心交給小模型批次跑,驗收這層的標準我目前還只信得過 Claude Code 跟 Codex。今天早上 Codex 那條斷掉之後,驗收就退化成 Claude Code 單腿撐,自己當 worker 又自己驗收這件事有它的限制,但短期沒更好的選項。
測試六鐵律#
驗收這層 Claude Code 要對照的,是我自己整理的六條測試規則。先把六條列出來,再交代怎麼長成今天這樣的:
- mutation thinking——測試要先想「這段 code 哪一行被改錯,這個 test 會不會炸」。如果不會炸,這 test 就是裝飾。
- 寫測分離——寫 code 的 agent 不能自己寫對應 test,要另開一個 agent 寫。同一個腦袋自我驗證盲區放最大。
- 不變量優先——優先測「跟舊行為對照不能變」的不變量,而不是「我預期會發生什麼」。預期可以錯,不變量比較硬。
- runtime → 回歸——測試一定要實際跑起來,不是 import check、不是 type check。能跑出 stack trace 的才算數。
- mock 只限外部 I/O 邊界——database、network、檔案系統可以 mock;內部模組之間禁止 mock。內部 mock 是 bug 的避風港。
- 草稿不是成品——AI 第一輪寫出來的測試是草稿,commit 前要再過一遍,問「這 test 真的會抓到 regression 嗎」。
來源與演進#
最初的種子是兩篇文章:
- How to Test AI-Generated Code the Right Way in 2026(Katerina Tomislav, 2026-02)——這篇講 AI 寫的測試最大病灶是「100% 行覆蓋率、4% mutation score」,覆蓋率好看但漏掉 96% 的 bug。引用 HumanEval-Java 的研究數據。
- Salesforce VIBEPASS——一個 benchmark,發現前沿 LLM 在沒被預先告知有 bug 時,從程式碼裡找出並修復隱性 bug 的成功率不到 50%。換句話說,AI 自己寫的測試大機率抓不到自己代碼的問題。
原文(Katerina)原本提出的是 4 條方向:mutation testing、AI-aware code review、CI pipeline validation、prompt engineering。我看完之後從第一條 mutation testing 開始套用,自己又從踩坑經驗加了幾條:
- 第一輪加上「寫測分離」——實測過自己寫的 27 個測試全過、改派獨立 sub-agent(不給它看實作)寫,立刻發現 2 個真實 bug。
- 第二輪加上「不變量優先」——固定 I/O pair 是同義反覆,只有 invariant 才獨立於實作。
- 第三輪加上「runtime → 回歸」「mock 只限外部 I/O」——這兩條都是 bug 被 mock 包成「測試過」之後在 production 爆掉踩出來的。
- 最後加上「草稿不是成品」——因為 Salesforce VIBEPASS 那條結論:AI 自己寫的測試不可盲信,commit 前必須過一遍。
到這就六條了。驗收提示詞會把這六條塞進 system prompt,要求 Claude Code 對 worker 交出來的 diff + tests 逐條檢查,違反哪條、為什麼違反、怎麼修,全部列出來。Codex 那邊不認這六條,所以 Codex 跑的是「純程式碼的 bug 與規範」這個正交的視角——這也是為什麼兩個 model 配在一起比一個 model 跑兩次有用。
為什麼是五家官網,不是 OpenRouter#
要做這套工作流,「找誰當 worker」是個關鍵題。最先想到的是 OpenRouter 這類 aggregator——一個 SDK、一條金流、所有 model 一次接完。看過 koc.com.tw 那篇供應商比較 之後更覺得方向順。
但實際算下來四個扣分:
- 加價層吃掉官方 promo。中間商加價 5%-20% 看起來不多,但每家原廠的活動、新戶額度、限時折扣全部拿不到。
- 官網限定額度拿不到。DeepSeek、Qwen、Moonshot 都發過新戶或活動贈送 token,必須是直接帳號才領得到。
- 金流黑盒、debug 難。出錯分不清是中間商 routing 還是 upstream provider 故障。
- prompt / response 加工的不確定性。中間商有沒有改 system prompt、tool schema、stream chunking?這對「評估每家原生表現」是噪音——我原本的好奇心之一就是想直接看每家原生水準,這條讓我直接放棄中間商方案。
最後挑的五家直接帳號:
- Moonshot(Kimi)——Agent 任務、深度推理(Kimi K2-Thinking 在 BrowseComp / AIME 領先)
- Z.AI(GLM)——中文長文(Arena Chinese 排名最高)
- DeepSeek——CP 值最高的 worker 主力($0.28/$0.42 預設背景任務)
- xAI(Grok)——寫程式 + 2M context 旗艦(SWE-Bench 領先)
- 阿里(Qwen via DashScope)——極速低成本(qwen3.5-flash $0.10/$0.40 是全場最低 input 價)
後來又補了 MiniMax 跟 Google Gemini,主要是想讓 fallback chain 更深。
Google Developer Program 抵免額#
Google 那條值得單獨提一下。我加入 Google Developer Program 之後,Premium tier 每個月都會發 $10 monthly Gen AI & Cloud credits 抵免額(一次性抵免、有效期一年),可以直接抵掉 AI Studio 跟 Vertex AI 的 Gemini API 用量。
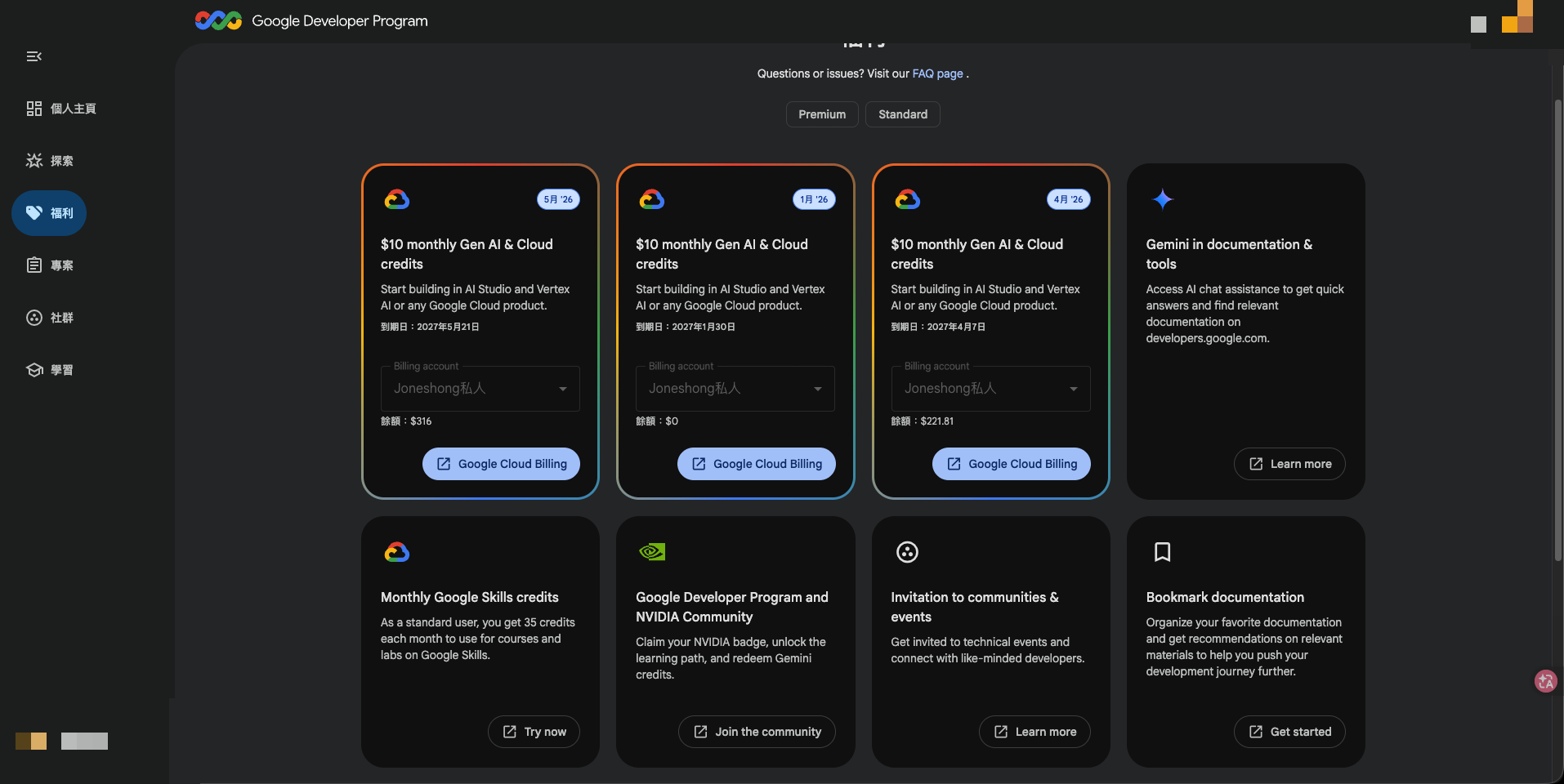
這些抵免額在 Google Cloud Billing 後台看得到核發紀錄,每張面額 $315-$320 不等,加總月度有 $300+ 可以打 Gemini API:
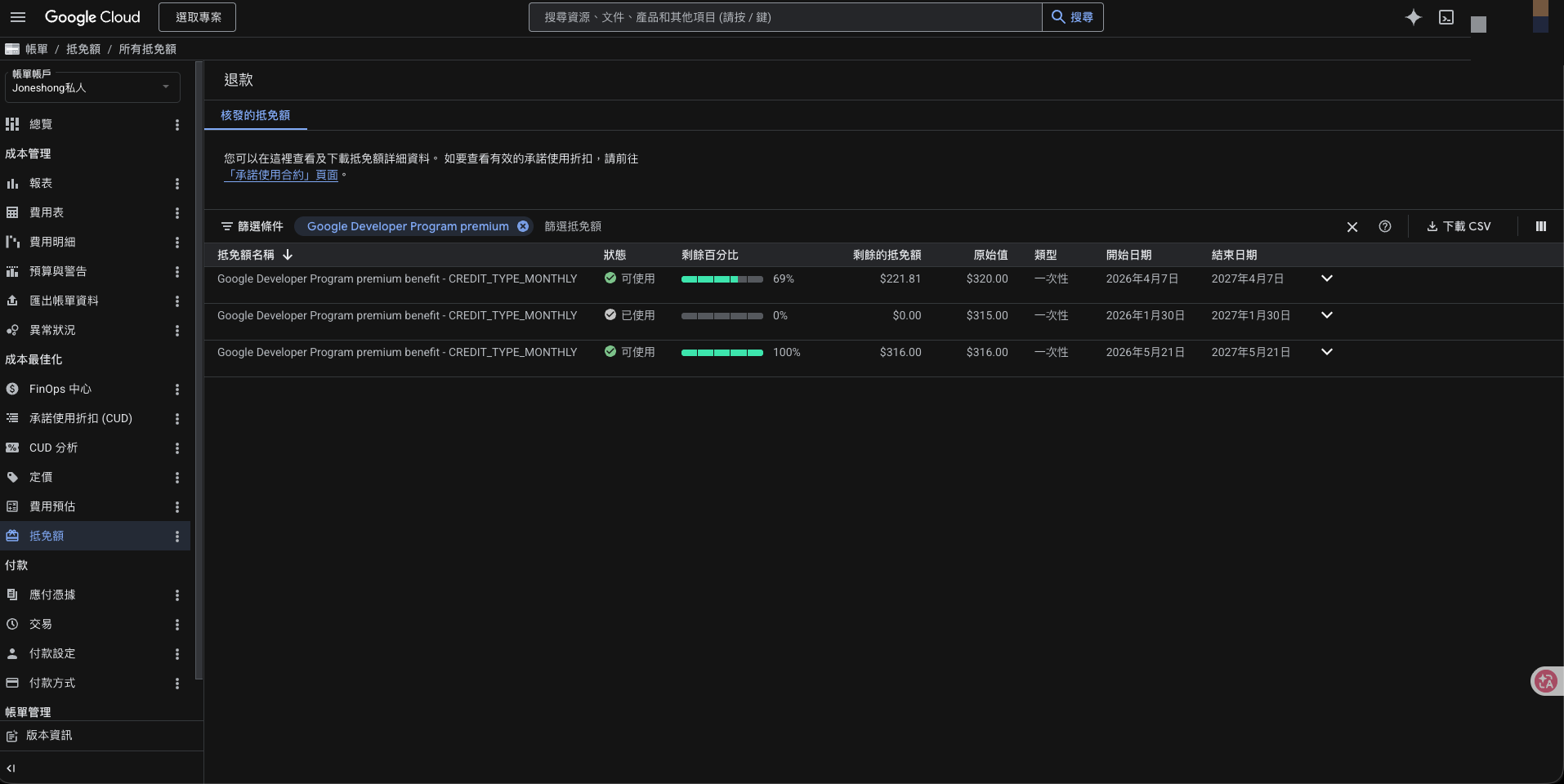
換句話說,把 Gemini 接進 LiteLLM 之後,這個閘道上「免費 model」那一欄就自動有了——配額爆的時候用 gemini-2.5-flash 接 worker 不用心疼成本。這是「直接買官網」這條路額外送的福利,走 OpenRouter 拿不到。
為什麼介面選 CCR:因為還是想用 Claude Code#
挑完 worker,接下來是「用什麼介面跑」。這陣子我把主流 CLI agent 都試了一輪——Codex、Gemini CLI、Copilot CLI 是固定班底,opencode、qwen-code、Aider、cursor-agent 也玩過。
結論是 Claude Code 還是最順手。tool use 的設計、subagent 機制、skill / slash command 體系、與 git worktree 的搭配、context 管理、permission flow 整體還是領先一截。如果其他 model 我也想跑,最理想是「換掉模型、留下介面」。
最初我其實只想「LiteLLM + 一段 zsh function」就解決——把 Claude Code 的 ANTHROPIC_BASE_URL 指到 LiteLLM :4000,自己改改 request body 就好。實際開始寫才發現每家協議的細節差很多:Anthropic 的 messages API 跟 OpenAI chat/completions 在 system message、tool definition、stream chunking、reasoning content block 上的格式都不一樣,每一處不對齊都會 400 或 silent 丟訊息。我大概寫了半天 transformer,意識到這事不該自己做——就是這時候找到 claude-code-router(簡稱 CCR)這個現成的 transformer。
CCR 在本機跑一個 :3456 的 server,對 Claude Code 表現得像 Anthropic API,對下游則把請求 transform 成 OpenAI 協議丟給 LiteLLM。從 Claude Code 角度看,它「以為」自己在跟 Anthropic 講話,實際上請求被路由到 DeepSeek、Kimi、Grok。換句話說,CCR 讓我可以用 Claude Code 介面,去跑任何 LiteLLM 上的 model。介面不用換、肌肉記憶不用重練、subagent / skill 體系全部繼承過去。
為什麼不用 cc-switch#
中間也試過 cc-switch 這個社群工具——一鍵切 Claude Code provider,看起來剛好對我的需求。實裝後發現它的切換機制是直接改 ~/.claude/settings.json:
~/.claude/settings.json是 Claude Code 全域單一檔。切一次,整台機器上所有 Claude Code session 都跟著變。- 我的工作流大量靠 tmux 多 pane 並行——一個 pane 跑 Kimi 規劃、一個 pane 跑 DeepSeek worker、一個 pane 跑 Grok 處理長 context。cc-switch 切第一次三個 pane 都變成同一家,切第二次又全變成另一家,根本沒辦法「並行不同 model」。
CCR + ENV var 路線恰好相反——ANTHROPIC_BASE_URL 跟 ANTHROPIC_MODEL 是 per-process 環境變數,每個 tmux pane 是各自獨立的 shell,互不干擾。下一節的 cc-llm 就是吃這個機制:
Pane A: cc-llm kimi-k2-thinking → 該 pane shell 設 ANTHROPIC_MODEL=litellm,kimi-k2-thinking
Pane B: cc-llm glm-5 → 該 pane shell 設 ANTHROPIC_MODEL=litellm,glm-5
Pane C: claude(不用 wrapper) → 該 pane 沒設 ENV,走 CCR 預設 routing
實際長這樣——一個 tmux window 垂直四欄,每欄一個 Claude Code,各打不同 model:
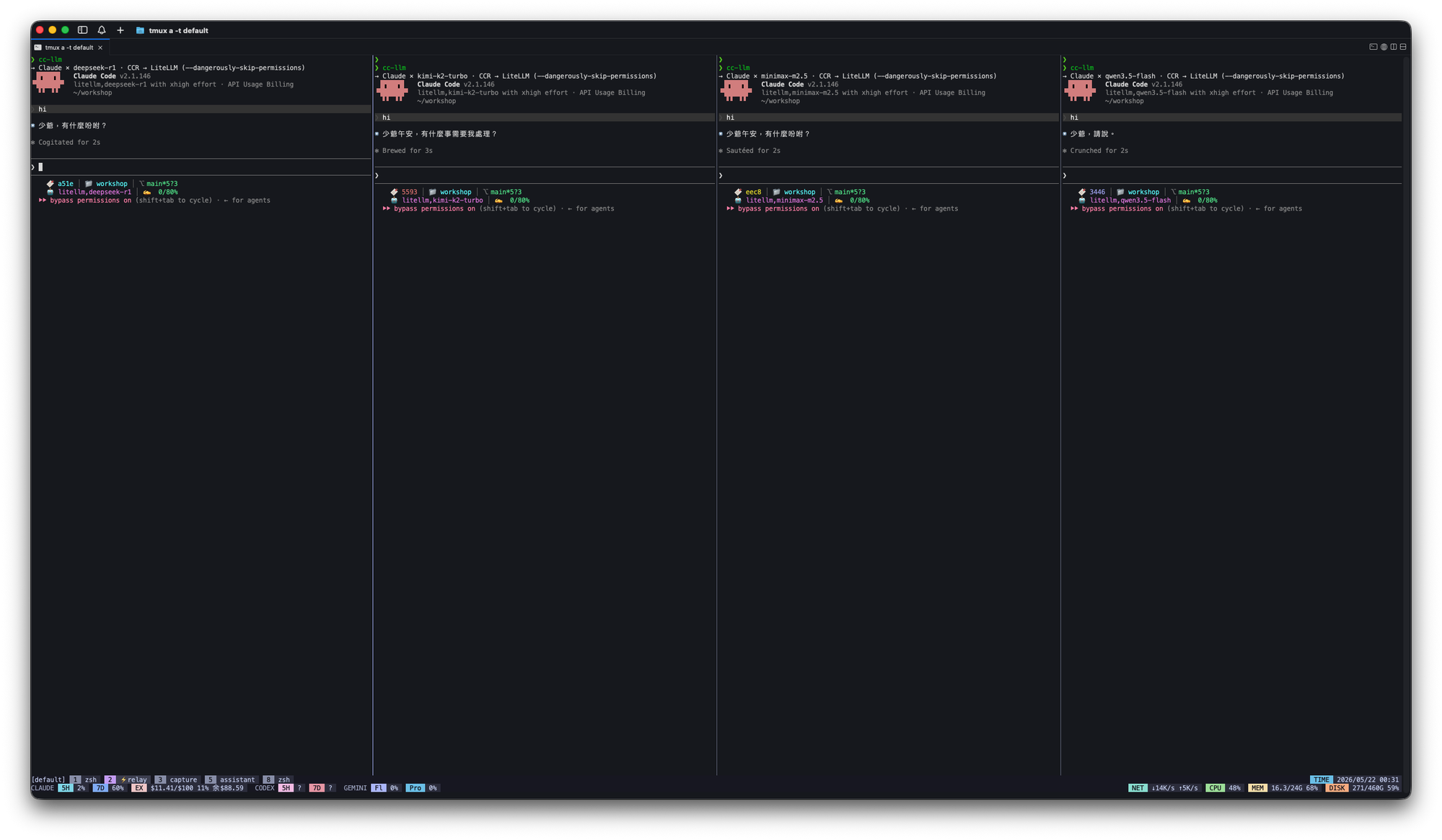
statusline 看得到每個 pane 各自的綁定:litellm,deepseek-r1、litellm,kimi-k2-turbo、litellm,minimax-m2.5、litellm,qwen3.5-flash。四個 pane 同時跑、各打不同 model,CCR :3456 只是個 proxy 看請求路由,不在乎是哪個 pane 發來的。~/.claude/settings.json 也完全沒被動過——所有切換留在 shell session 裡。對「同一台機器同時跑多個 model」這個場景,CCR 是現有方案裡唯一做得到的。
技術骨架:LiteLLM + CCR + 自製 zsh function#
把前兩節的選擇兜起來,整套路由長這樣:
Claude Code (Anthropic protocol) ─→ CCR :3456 ─→ LiteLLM :4000 ─→ providers
Codex / Gemini / OpenCode ─────────────→ LiteLLM :4000 ─→ providers
LiteLLM 是唯一閘道。所有 model_list、API key、fallback、cost telemetry 集中在一份 config.yaml,每家 provider 一個 entry,API key 全用 env var 引用。長相像這樣(節錄一條 entry 意思到即可):
model_list:
- model_name: deepseek-v3 # 預設 worker
litellm_params:
model: deepseek/deepseek-chat
api_key: os.environ/DEEPSEEK_API_KEY
# ...kimi / grok / glm / qwen 結構類似,差在 api_base 與前綴
litellm_settings:
drop_params: true # 某家不支援的 param 自動 drop,免 400
modify_params: true # max_tokens 自動對齊 model 上限
spend_tracking_enabled: true
router_settings:
fallbacks:
- grok-4.20: [deepseek-v3, kimi-k2-thinking]
- glm-5: [kimi-k2.5, qwen3.5-122b]
drop_params + modify_params 是踩坑後加上去的「免 400」雙保險,省去手動對齊每家 param schema 的工。fallbacks 設好之後,A model 收 429/5xx 自動切 B。
CCR 那邊 config.json 結構更簡單,最關鍵的是 Router 區塊把任務型態對應到具體 model:
"Router": {
"default": "litellm,deepseek-v3", // 背景任務最便宜
"think": "litellm,kimi-k2-thinking", // 需要 reasoning
"longContext": "litellm,grok-4.20", // > 60K token 轉 2M window
"longContextThreshold": 60000,
"webSearch": "litellm,qwen3.6-plus"
}
最後是讓一切變一行指令的自製 zsh function cc-llm(脫敏骨架):
cc-llm() {
local model="" flags=()
# 解析 [model] [flags...]
while [ $# -gt 0 ]; do
case "$1" in
-*) flags+=("$1"); shift ;;
*) [[ -z "$model" ]] && model="$1"; shift ;;
esac
done
# headless 模式需要這個(CCR 會頻繁問權限)
flags+=(--dangerously-skip-permissions)
# 沒指定 model 就 fzf 開選單
if [[ -z "$model" ]] && command -v fzf >/dev/null; then
model=$(_list_models | fzf --prompt="cc-llm › " | cut -f1)
fi
# 切 endpoint + 鎖定 LiteLLM 上的 model
ANTHROPIC_BASE_URL=http://127.0.0.1:3456 \
ANTHROPIC_AUTH_TOKEN=any-string-is-ok \
ANTHROPIC_MODEL="litellm,$model" \
claude "${flags[@]}"
}
實際用起來,cc-llm 直接呼叫會開 fzf 選單,自動撈 LiteLLM 上目前所有可用 model,按 provider 分群顯示:
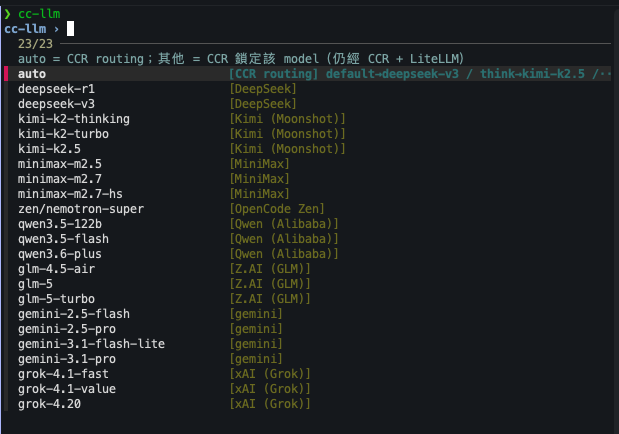
選了某個 model 後,Claude Code 啟動進 TUI,statusline 會明確標出走的是哪條路、用的是哪個 model、effort 設多少:
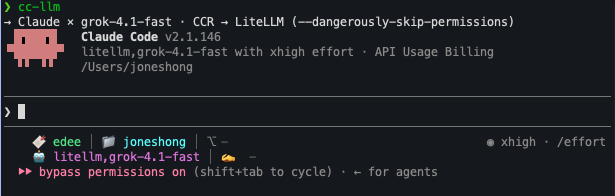
例如上面這張,標題列「Claude × grok-4.1-fast · CCR → LiteLLM」就是 zsh function 印出來的訊息,狀態列下方「litellm,grok-4.1-fast」是 Claude Code 自己讀 ANTHROPIC_MODEL 顯示的,effort 鎖在 xhigh、bypass permissions on——確認這些跟預期一致,就可以放心開工。
其他用法:
cc-llm deepseek-v3 # 跳過選單,鎖定 deepseek-v3 跑 worker batch
cc-llm grok-4.20 --effort high # 鎖 Grok + 高 reasoning
同類還寫了 cx-llm(Codex)、gm-llm(Gemini CLI)、oc-llm(OpenCode),這三個協議跟 CCR 不相容,所以直連 LiteLLM。所有 CLI 都用一份 LiteLLM config.yaml,要加新 model 改一處。
連 subagent 也設次等模型#
Claude Code 內建 subagent 機制——主對話委派一段獨立任務給 subagent,subagent 跑完回傳結果,主對話繼續。subagent 的定義檔(~/.claude/agents/*.md)有個 model: 欄位可以指定要用什麼模型跑這個 agent。
我在四個「跑簡單任務的 agent」上把 model 從預設 sonnet 改成 haiku:
| Agent | 用途 | 改後 model |
|---|---|---|
explorer |
codebase 搜尋、找檔案 | haiku |
researcher |
web 搜尋、資料整理 | haiku |
browser |
Playwright CLI browser automation | haiku |
media |
影音/圖像/OCR 處理 | haiku |
這四種任務的共通點:tool call 多、reasoning 淺、需要的 model 智力不高,但會吃大量 turn 跟 context。原本全用 sonnet 跑,配額消耗驚人;換成 haiku 之後成本砍掉九成,品質沒明顯掉。
更聰明一點的是動態調整——我寫了個 model-policy daemon 每 5 分鐘看一次 Claude 配額剩多少,分四階:normal / boost-1 / boost-2 / boost-3。配額充裕時 haiku 就是 haiku;配額快爆(5h < 25% 或 7d < 40%)時自動把 haiku 升 sonnet、sonnet 升 opus,讓「能用大 model」的時候用滿、「該省的時候」自動降階。
這層分工是「Claude Code 內部」的:主對話還是 sonnet/opus 規劃,但分派出去的 subagent 跑簡單任務時走 haiku。和 LiteLLM 的「外部 worker」是兩條獨立的省配額路徑,可以疊加。
監控:知道每個 model 現在用了多少#
工作流接好了,剩下一個小問題——五家加上 Big-3 共八個 dashboard,每家網站排版都不一樣。隨手翻幾張各家後台給你看:
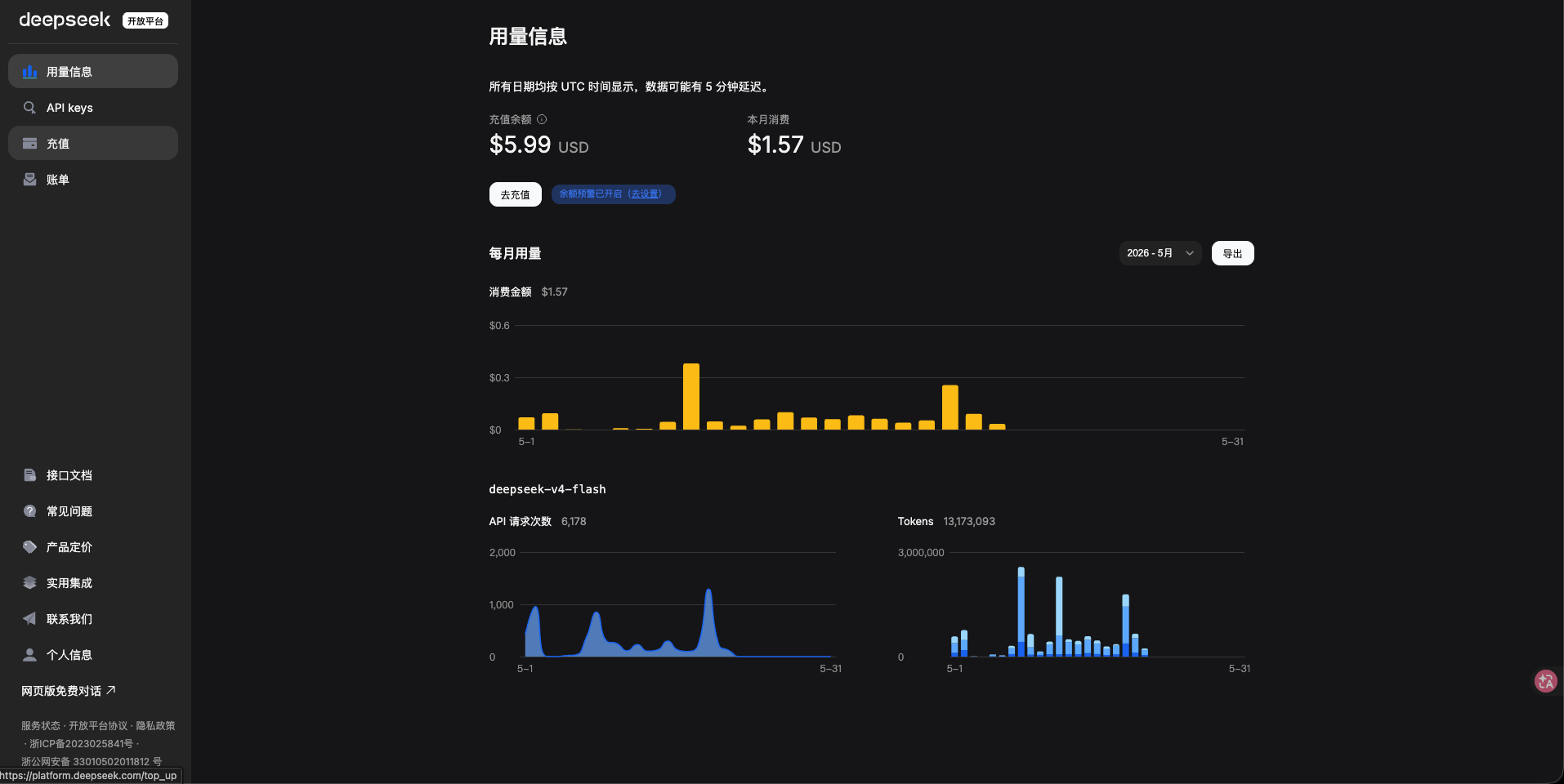
DeepSeek 是 prepaid 模式,給的是充值餘額 + 每日消費長條圖:
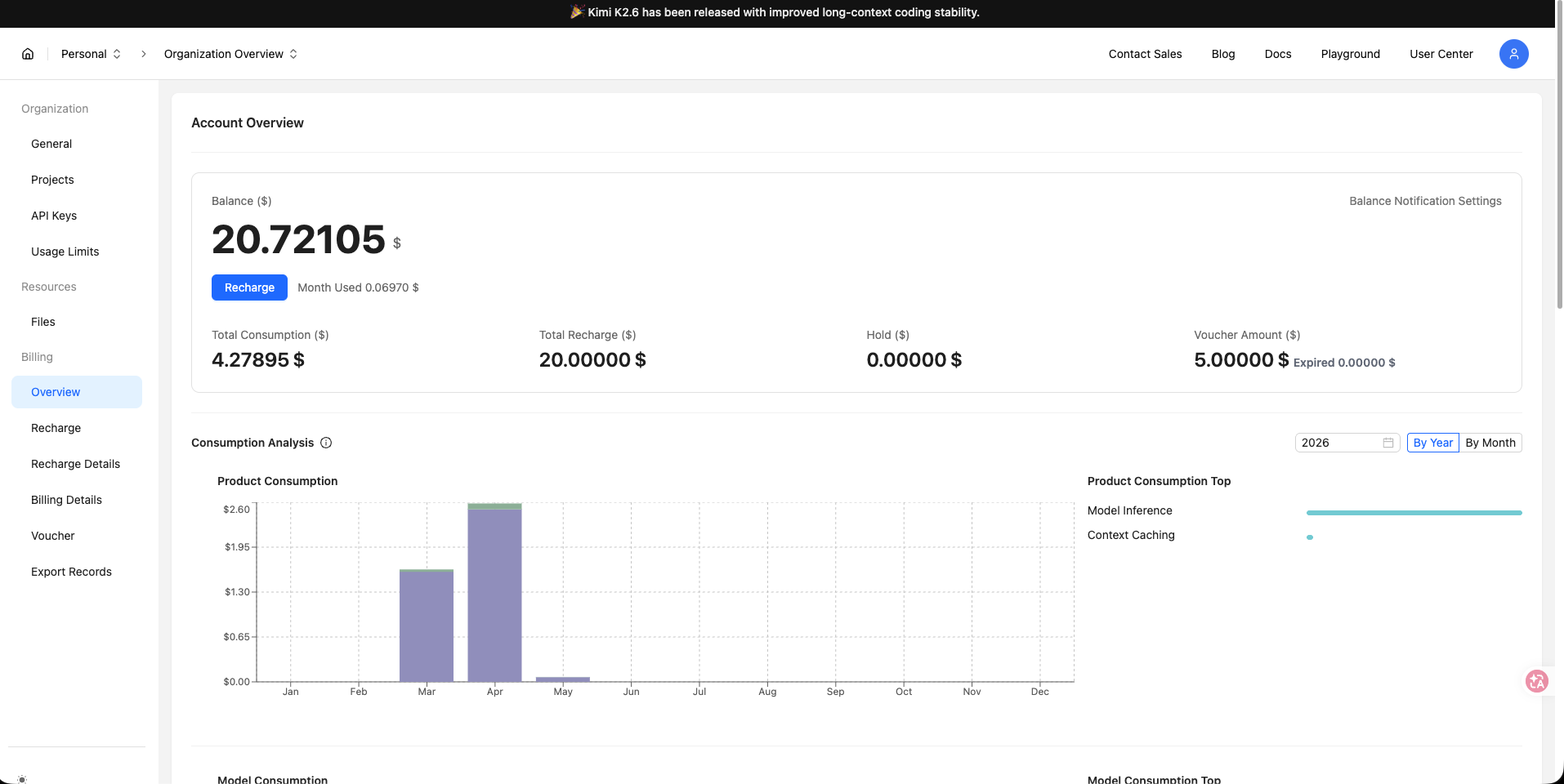
Moonshot(Kimi)給的是 Balance + Voucher + 每月 Product Consumption 折線:
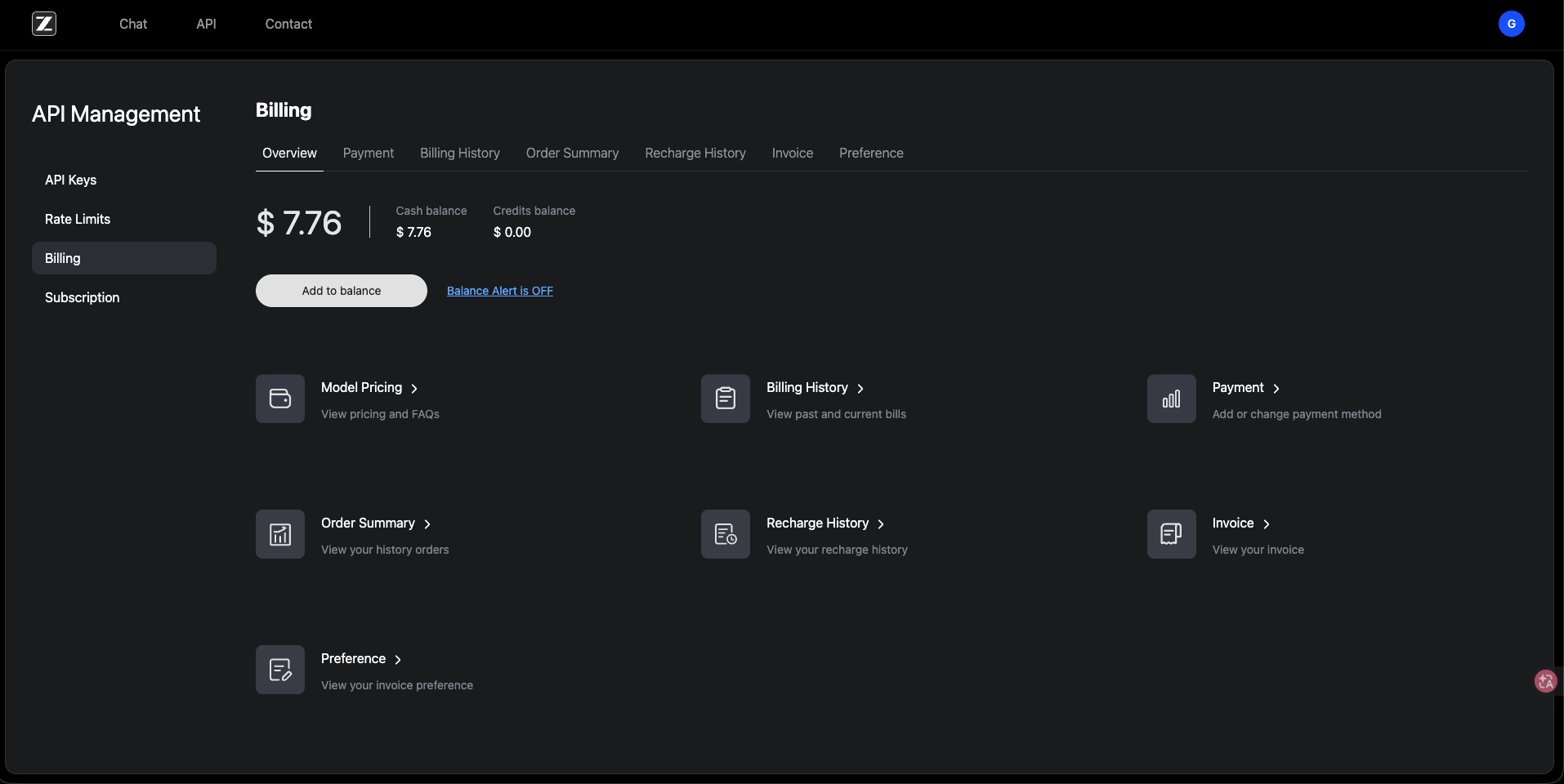
Z.AI(GLM)給的是 Cash balance + Credits balance 兩個獨立帳戶:
MiniMax 把 Current balance / Voucher / Overdraft limit / Outstanding 分四欄,加減乘除自己算:
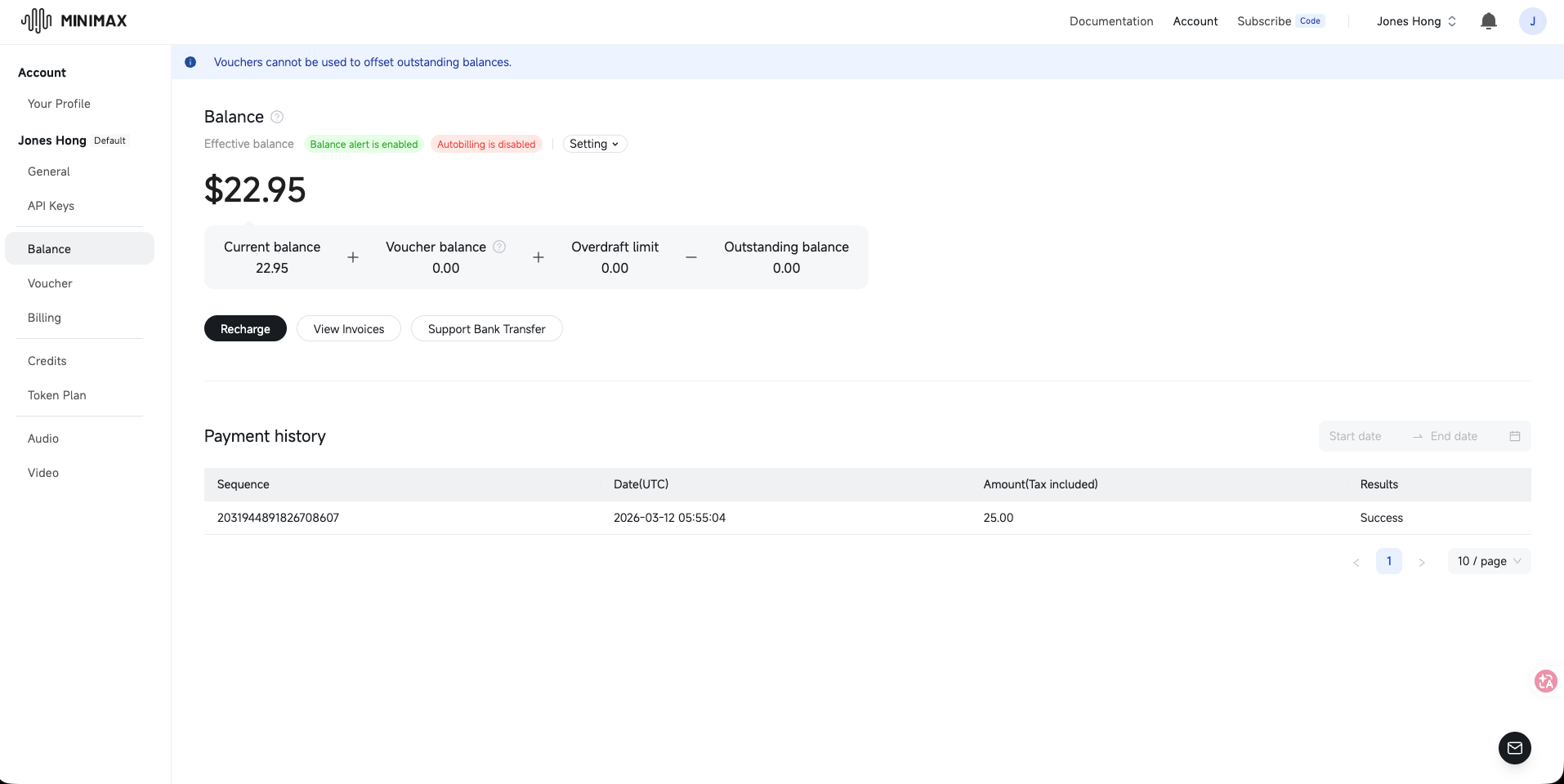
xAI 顯示 Spend credits + Auto top-ups + Latest invoices 三段:
阿里 DashScope 走的是「每個 model 各自有免費額度」的設計,82 個 model 各看各的剩餘 token:
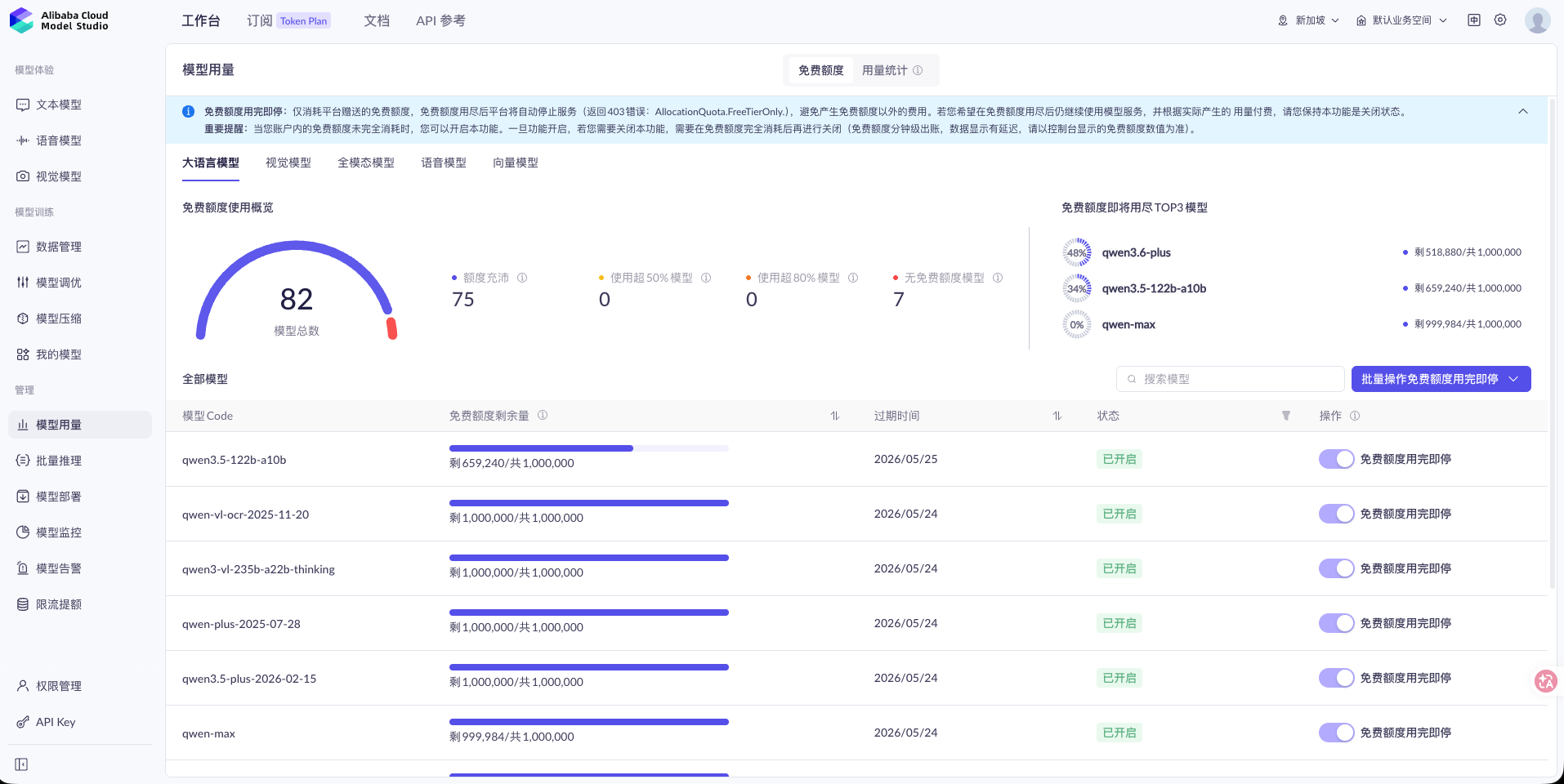
每家設計邏輯都不一樣——「我下一個任務該丟誰」這個問題沒辦法在任何一家後台回答,要嘛開六個分頁手動比,要嘛自己整合。
於是自己拼了個小監控頁,每天定時爬一次餘額。三個 view:
配額 view——把訂閱型額度(Claude 5h/7d/EX、Codex 5h/7d、Gemini Pro/Flash 24h)跟 reset 時間擺一起:
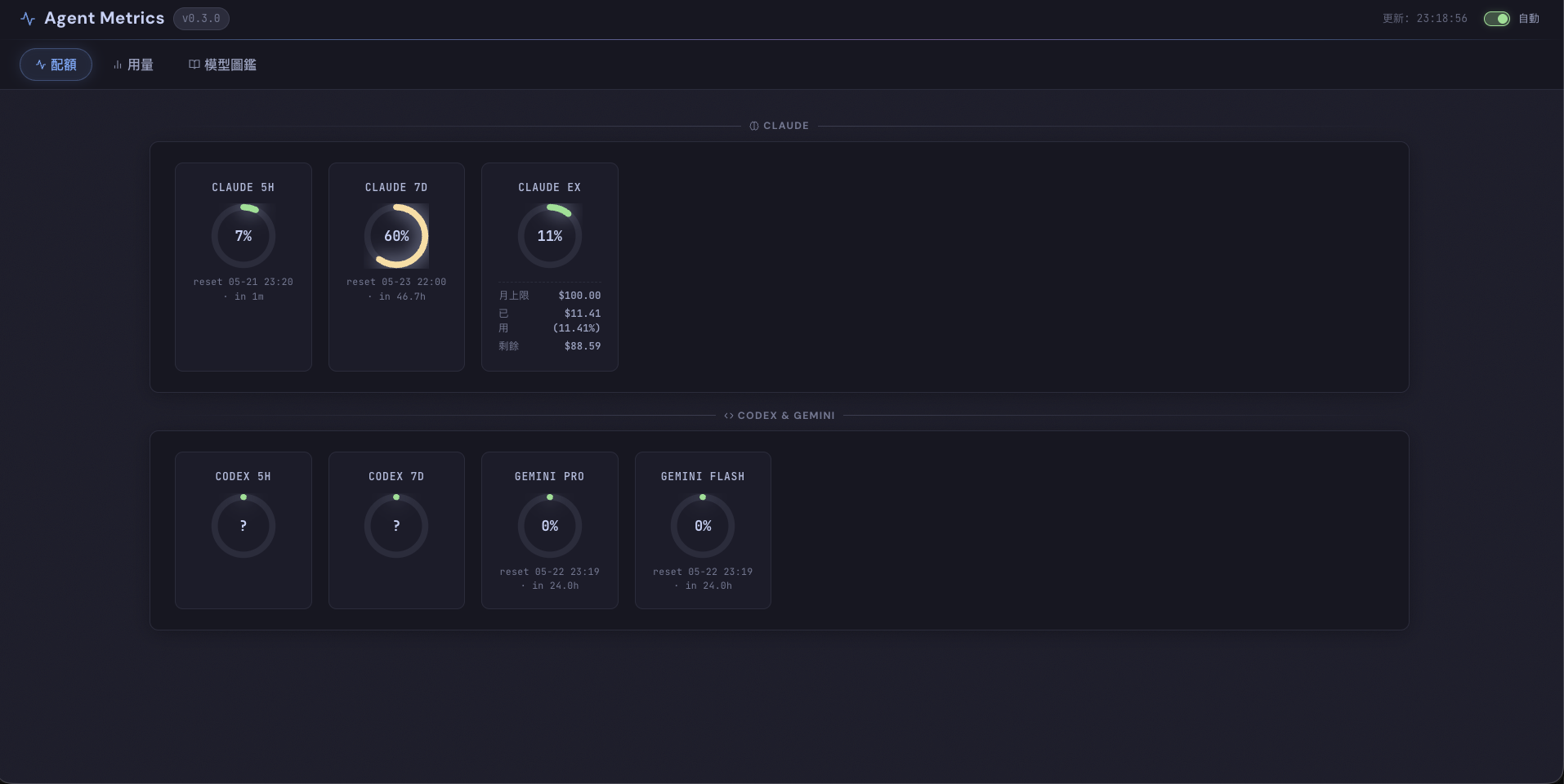
我看一眼就知道:Claude 5h 才吃 7%(馬上要 reset)、7d 已經吃掉 60%(距下次 reset 還有約兩天)、EX 月上限 $100 才用 11%。要繼續拼還是先換 worker model,這頁就能決定。
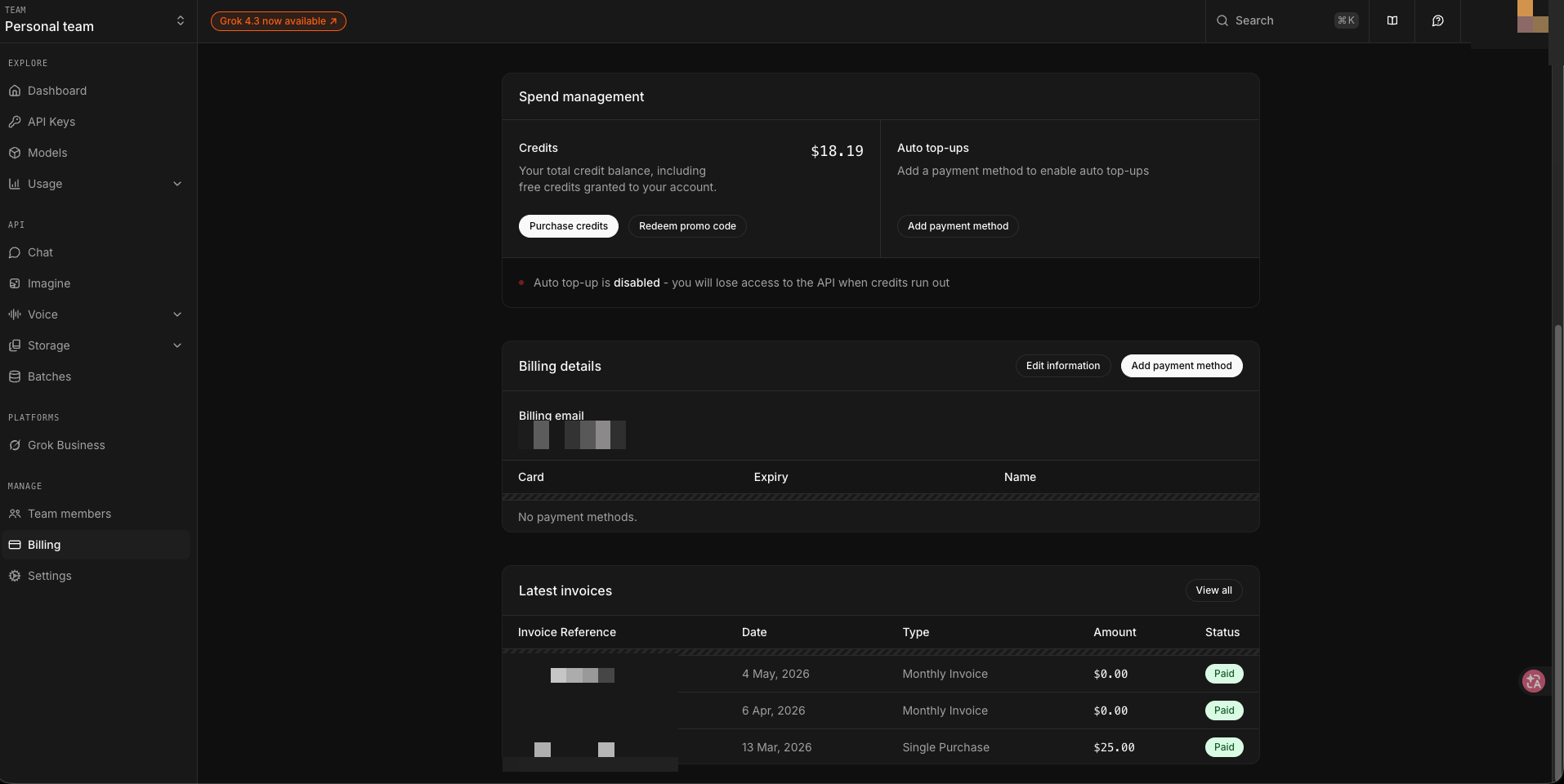
用量 view——LiteLLM 預付額度、每家 provider 儲值 / 剩餘 / 已用 / 使用率攤平:
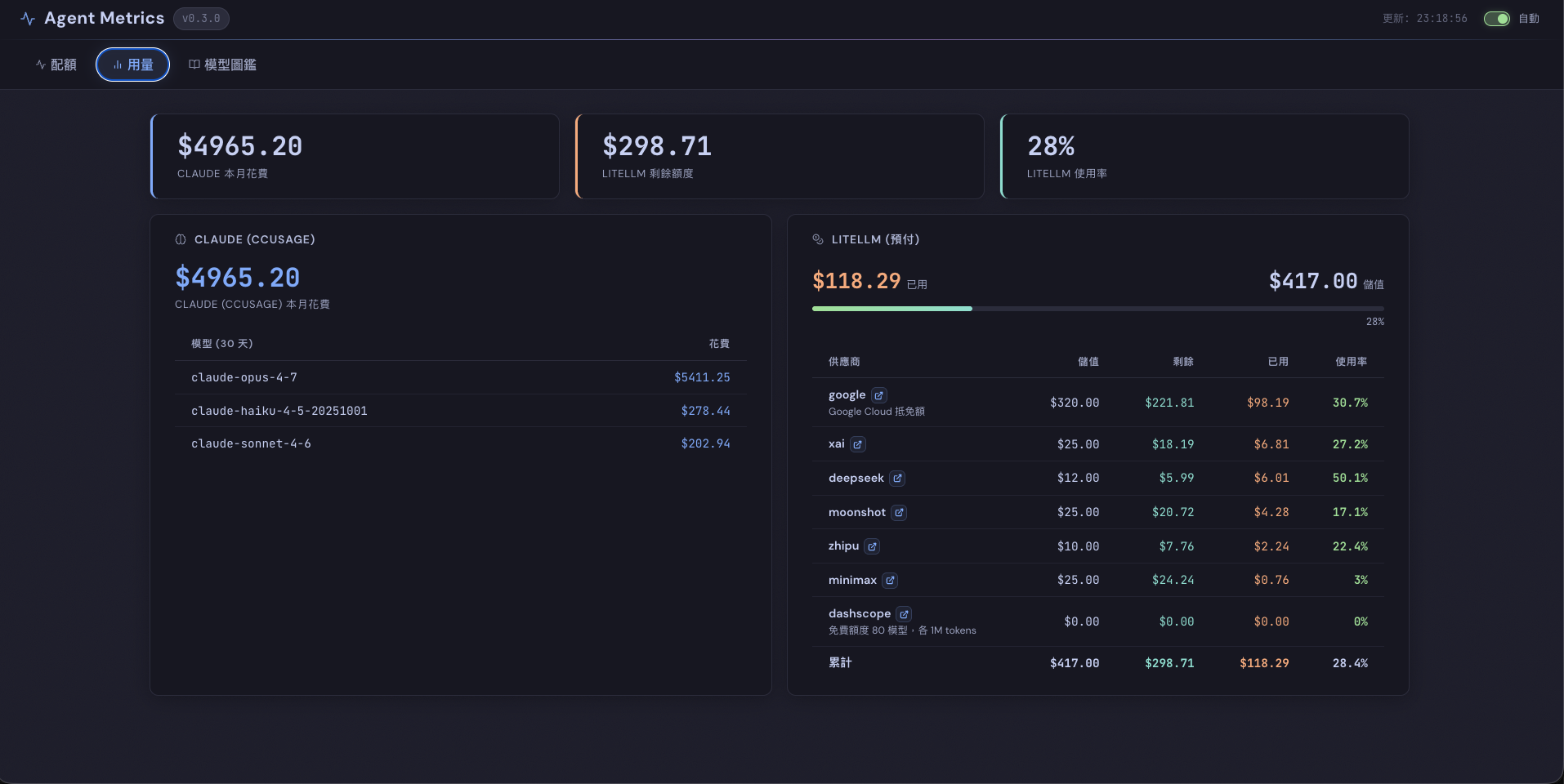
這頁我看得最頻繁。DeepSeek 已用 50%、Moonshot 才 17%、MiniMax 才 3%——這意味著 DeepSeek 接太多 batch task 了,下次可以把一部分分散到 Moonshot 或 MiniMax,避免單一 provider 先燒完。Google Cloud 抵免額也納入這頁(免費的,但「快用完」要追)。
模型圖鑑 view——各家旗艦 / Fast / Value 模型一覽,加上 Arena / SWE-Bench / Speed 場景推薦:
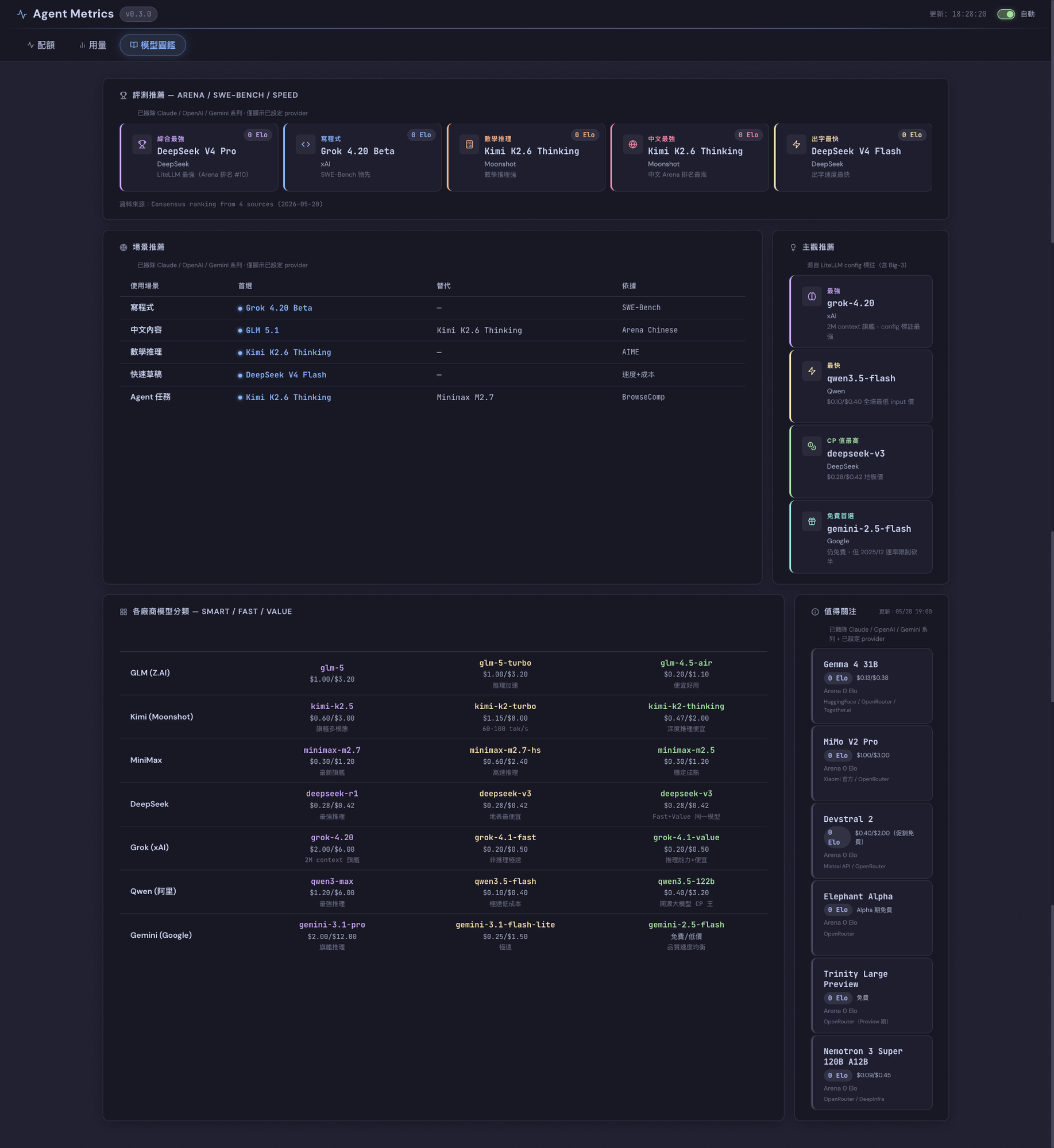
這頁每隔幾天更新一次(Consensus ranking from 4 sources),用來決定「現在哪個 model 該路由到什麼任務」。2026-05-20 那天,數學推理首選從 DeepSeek R1 換成 Kimi K2.6 Thinking——換完 LiteLLM config.yaml 跟 CCR Router 同步更新。
比對 provider model list 偵測「設定過時」#
爬蟲還順帶做第四件事——抓每家 provider 官網的 /v1/models endpoint,跟 LiteLLM config.yaml 裡寫的 model_name 對照。這條是踩過坑才補的。
過去發生過好幾次:早上開 Claude Code 跑工作,CCR :3456 回 404 model not found;查半天才發現某家供應商把 xxx-preview 改成 xxx-stable、或者把舊版本 v3.1 直接退役換成 v3.2——LiteLLM config.yaml 還寫著舊名字,於是整條路徑斷掉。前沿模型替換速度比想像中快,DeepSeek、Moonshot、Qwen 一兩週就可能換一輪 model code,新舊命名常常沒回溯相容。
對照邏輯很單純:
# 每天定時跑
for provider in providers:
upstream_models = fetch(provider.list_endpoint) # e.g. https://api.moonshot.cn/v1/models
configured = read_litellm_config()[provider.name] # 我寫進 config.yaml 的 model 名
stale = configured - upstream_models # 在我 config 但 upstream 沒了 → 已退役
new = upstream_models - configured # upstream 新出但我沒接 → 候選
dashboard 把 stale 標紅、new 標綠,一眼就知道「config 哪幾條已經失效該砍 / 哪幾條新出可以評估」。這條 check 從事後 debug 變成事前預警之後,「啟動才發現 model 404」這個情境就消失了。
後端就是每天一輪爬蟲,前端是個自己拼的小單頁。寫它的動機不是技術秀,是因為這資訊現有工具沒人整合,自己想看只能自己刻。
Trade-off:誰適合、誰不適合#
好處有三條:
- 三層分工 ROI 對齊——規劃這層留最聰明的 model、worker 用 $0.2/$0.5 級別的批次跑、驗收用兩個 model 交叉。同樣的配額能多撐幾天,結果品質還比一個 model 從頭打到底穩。
- 「順便了解其他模型」是 bonus——試了一陣子,對哪家在哪類任務上比較強有了一手感覺,不用只看別人的 benchmark 圖。模型圖鑑那頁就是這套手感累積出來的。
- 單一 provider 斷供不會整套停——像今早 Codex 那樣被鎖住,工作流會降級成單腿驗收,但 Claude Code + LiteLLM 兩條線繼續跑得動。
代價也三條:
- 多了 CCR 跟 LiteLLM 兩個 daemon 要維護。CCR 升版改過 transformer schema、LiteLLM 1.55+ 改過 spend tracking 欄位,每次都得回去 debug 半天。
- 每家 provider 的個性要自己摸——Moonshot 偶爾延遲飆高、DashScope 偶爾 5xx、xAI 有過幾次回應格式漂移。fallback chain 沒設好就會踩到。
- 「哪個 task 該跑哪個 model」沒人替你決定——多了一層心智負擔,要嘛靠經驗、要嘛靠模型圖鑑這種輔助工具。
所以這套適合的是:20x 訂閱真的不夠用、又願意花一個週末把架構鋪好的人。如果 20x 用著很舒服、或者不想多養兩個本機 daemon,就維持原樣最省心——這套的代價超過它的好處。
我自己留下來的理由就一句:對「同樣的任務換不同的 model 跑會發生什麼」這件事的好奇還沒退,分工跑下來也確實對配額更友善。配額用完不會逼自己升訂閱、會逼自己想清楚哪一層在燒——這種「被資源限制推著思考」的感覺,反而是我最喜歡的部分。
複製給你的 AI Agent(想試試多 model worker 工作流的人):
我目前的 AI 寫程式工作流主要靠 [Claude Code / Codex / Cursor / ...], 訂閱配額一週見底 N 次。請幫我評估是否值得拆成「規劃 / worker / 驗收」三層分工: 1. 從我過去 30 天的 token 用量找出「不該用旗艦 model 跑」的任務類型 (批次改檔、翻譯、grep 整理、boilerplate 生成、機械式重複)。 2. 估算這些任務搬到 LiteLLM 上 $0.2/$0.5 級別的便宜 worker(DeepSeek V3 / Qwen Flash / GLM Air)之後,每月可省多少配額或現金。 3. 檢查我現在的 provider 組合有沒有「single point of failure」—— 今天某家 API 突然斷供 24 小時,工作流哪個環節會卡住? 4. 設計驗收層:哪兩個獨立 model 適合做 cross-review? 一個照 coding rules 跑、一個直接看 git diff,各自的盲區互補。 5. 漸進過渡步驟:先架 LiteLLM(一份 config.yaml)→ 接一家 provider 試 → 寫一段 cc-llm 之類的 wrapper → 再決定要不要上 claude-code-router。 6. 維護代價:每天一輪爬蟲偵測「provider 換 model code 害我設定過時」、 兩個 daemon 升級踩坑、多 model 心智負擔。提醒我衡量值不值。
延伸閱讀#
- claude-code-router — Anthropic ↔ OpenAI protocol transformer。沒它 Claude Code 進不了 LiteLLM,是整套路由的關鍵中介層。
- LiteLLM — 多 provider 統一閘道。本文整套架構的核心。
- cc-switch — 走過但放棄的方案。看一下 README 就知道為什麼它對「同時多 model 並行」做不到——設計前提是「整台機器一時一個 provider」。
- koc.com.tw 各家 AI API 中間商比較 — 中間商方案的入門概覽,看完它我決定不走中間商。
- How to Test AI-Generated Code the Right Way in 2026 — 「測試六鐵律」的最早種子。「100% coverage / 4% mutation score」這個對比講清楚之後,我對 AI 寫的測試就再也不敢盲信。
- Salesforce VIBEPASS — benchmark 顯示前沿 LLM 找自己代碼裡隱性 bug 的成功率不到 50%。這是「驗收這層不交給小模型」最硬的證據。
- tmux 從通用狀態列、分屏、遠端到多 agent 分工 — 本文「tmux 四欄並行不同 model」那張截圖背後的工具鏈怎麼長出來的。如果你還沒用 tmux 跑多 agent CLI,這篇講基礎佈局與狀態列。
推薦閱讀
tmux 從通用狀態列、分屏、遠端到多 agent 分工
2026 年 2 月被 openclaw 啟發開始用 tmux,從狀態列、分屏、遠端開發一路堆疊到多 agent 分工
memvault 全景:三條軌道 × 三層心法
memvault 三部曲總集 — 把寫入、整理、召回三條軌道串成一張地圖,補上 CLT 認知負荷、4 Event Flows、RxJS Reactive 三層跨軌心法
想起來之後——AI Agent 怎麼越用越懂我
跨 session 的記憶提取,從「存得到」走到「叫得回」。三個情境、一條管線、疊了 11 層的排序。